
Mô hình dữ liệu và ngôn ngữ truy vấn
Data Models and Query Languages

Bài viết này lược dịch từ chương 2 cuốn sách “Designing data sensitive applications” của Martin Kleppmann
Mình vừa mở trang Buy Me a Coffee ☕. Nếu bạn thấy những bài viết của mình hữu ích và ý nghĩa, có thể ủng hộ tác giả bằng một ly cà phê nhỏ để mình có thêm động lực chia sẻ nhiều hơn 💙.
Mở đầu
Data model là cách mà các chúng ta nghĩ về các vấn đề mà chúng ta sẽ giải quyết. Mỗi data model được xây dựng dựa trên data model của lớp thấp hơn. Ví dụ:
Application developer: Nhìn các objects của thế giới thực và mô hình hoá thành cách objects hay data structure hay các API thảo tác trên các structure đó. Mỗi application sẽ có những structure khác nhau. Khi bạn muốn lưu trữ những structure này bạn phải sử dụng một “mô hình dữ liệu dùng chung” như JSON, XML, table trong relational database hay graph database.
Database developer: sẽ quyết định cách lưu trữ JSON/XML/Table/Graph thành từng byte trong memory, disk hay network. Các cách biểu diễn này cho phép data có thể truy vấn, tìm kiếm, thao tác hay xử lý theo nhiều cách khác nhau.
Hardware engineers: Ở level này, bạn sẽ quyết định cách biểu diễn từng byte dưới dạng các dòng điện, từ trường và nhiều thứ khác.
Một application phức tạp có thể build các API dựa trên các API khác, nhưng mà đều chung một ý tưởng: Trừu tượng hoá/đơn giản hoá sự phức tạp của các API ở level dưới bằng cách cung cấp một clean data model.
Có rất nhiều data model khác nhau, chỉ master một trong số chúng cũng đã rất khó (bạn thử đếm xem có bao nhiêu cuốn sách về chủ đề relational database).
Việc lựa chọn data model phù hợp với application của bạn là rất quan trọng.
Relational Model với Document Model
Data model nổi tiếng nhất có lẽ là SQL, dựa trên mô hình dữ liêu quan hệ, được phát triển từ những năm 1970. Data được lưu vào từng relations (bảng) mỗi relations có có tuple (dòng). Qua nhiều năm, với nhiều công nghệ khác, như network model, the hierarchical model hay XML databases… những relational model vẫn có chỗ đứng vững chắc trong các hệ thống ngày này, từ online publishing, discussion, social networking, ecommerce, games, software-as-a-service productivity applications và nhiều hơn nữa.

Không tương thích giữa object và relation
Nhà phát triển ứng dụng thường làm việc với các ngôn ngữ lập trình hướng đối tượng (OOP), trong khi dữ liệu lại được lưu trữ dưới dạng mô hình quan hệ. Vì vậy, cần có một lớp trung gian để ánh xạ giữa các đối tượng trong bộ nhớ và mô hình trong cơ sở dữ liệu. Các framework như Hibernate hay ActiveRecord có thể giúp giảm lượng mã cần viết cho việc ánh xạ này, nhưng vẫn không thể che giấu hoàn toàn những khác biệt giữa hai 2 models.
Trong ví dụ sau, một profile có thể được xác định bởi một ID duy nhất, first_name và last_name nhưng một profile có thê có nhiều positions, nhiều education record và nhiều contact info. Đó là mối quan hệ 1-n. Có nhiều cách để model mối quan hệ này.
Traditional SQL model: Đặt các thông tin như positions, education, and contact information sang một table khác và trỏ khoá ngoại về table user.
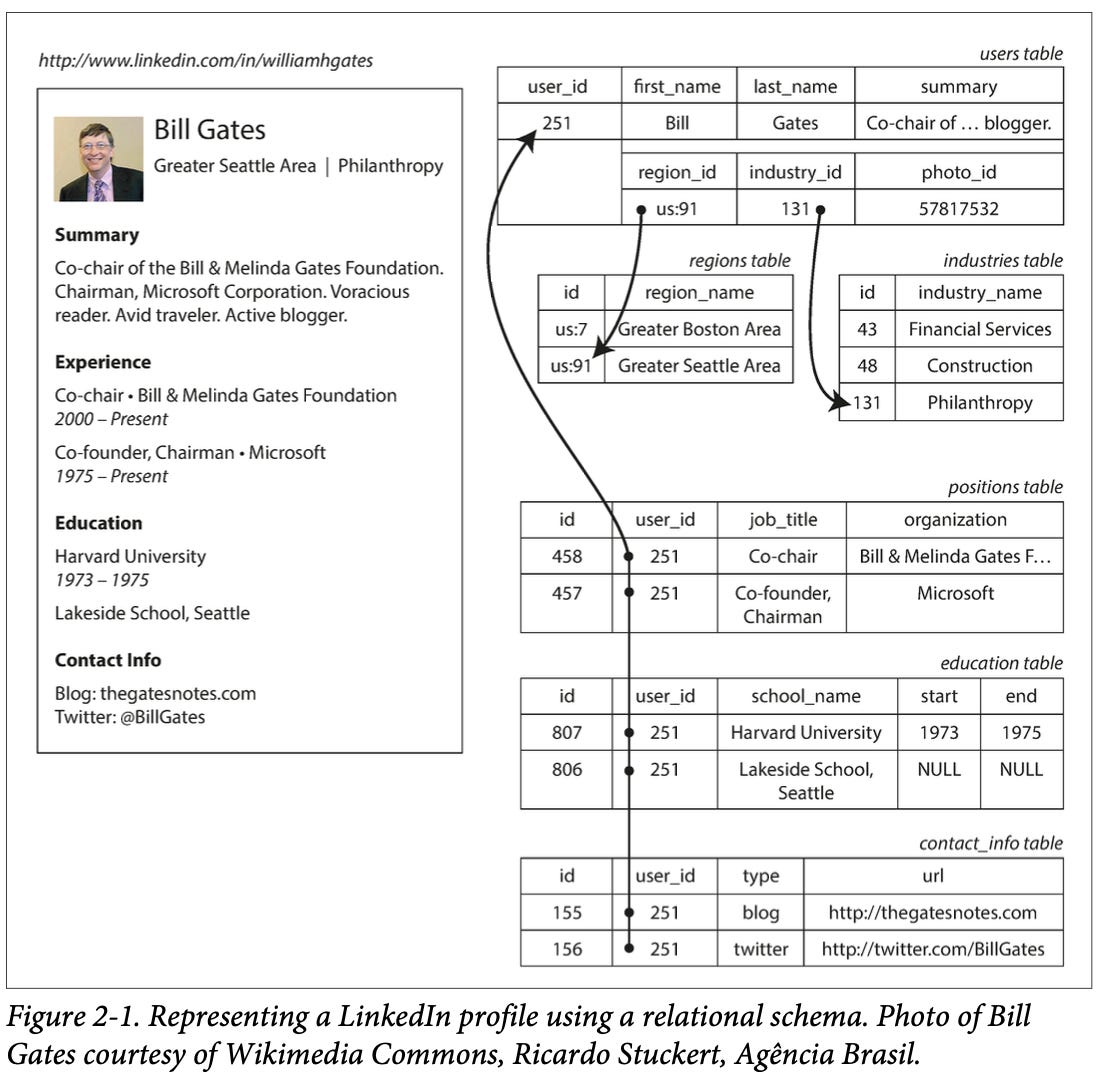
SQL model hiện đại cho phép data type của column là XML hoặc JSON, do đó cho phép “multi-valued” được chứa trong một dòng. Application có để đọc encoding string đó và tự decode nội dung. Tuy nhiên sẽ không thể sử dụng database để query nội dung trong các cột.
Document-oriented database, chưa các object dạng document, ví dụ với profile như trên sẽ được lưu như sau:
{ "user_id": 251, "first_name": "Bill", "last_name": "Gates", "summary": "Co-chair of the Bill & Melinda Gates Foundation. Active blogger.", "region_id": "us:91", "industry_id": 131, "photo_url": "/p/7/000/253/05b/308dd6e.jpg", "positions": [ { "job_title": "Co-chair", "organization": "Bill & Melinda Gates Foundation" }, { "job_title": "Co-founder, Chairman", "organization": "Microsoft" } ], "education": [ { "school_name": "Harvard University", "start": 1973, "end": 1975 }, { "school_name": "Lakeside School, Seattle", "start": null, "end": null } ], "contact_info": { "blog": "http://thegatesnotes.com", "twitter": "http://twitter.com/BillGates" } }
Many-to-One and Many-to-Many Relationships

Trong ví dụ trên, tại sao lại cần region_id hay industry_id mà không phải là free text region hay industry? Có một vài lý do để chuẩn hoá thông tin mà không cho user tự do nhập
Thống nhất tên và chính tả cho các profile khác nhau
Tránh nhầm lẫn (Ví dụ: nhiều thành phố có tên giống nhau)
Dễ dàng cập nhật, vì tên được lưu ở một nơi duy nhất, khi thay đổi chỉ cần thay đổi ở một nơi và tất cả mọi chỗ đều được cập nhật.
Search dễ dàng hơn
ID không có ý nghĩa với con người, con người chỉ quan tâm tới tên. Khi data lưu thông tin có ý nghĩa, nó có thể thay đổi trong tương lai. Và nếu data bị duplicate ở nhiều nơi, chúng ta phải thay đổi ở tất cả mọi nơi. Remove duplication là key idea trong data normalization.
Nhưng với mối quan hệ many-to-many, normalization không phù hợp trong document database. Ở relational database, việc lưu ID trỏ tới dòng ở table khác là hợp lý, vì co thể dễ dàng join query trong relation database. Nhưng join thường không được support hay support rất hạn chế trong document database.
Do đó, nếu database không support join, chúng ta thường tự join trên application level bằng cách viết nhiều câu query trong database và lưu data trong memory. Cần lưu ý có thể hiện tai ưng dụng của bạn hoạt động tốt trong một join-free document database, nhưng trong tương lai, với những yêu cầu mới, có thể sẽ không còn phù hợp nữa.
Relational Versus Document Databases Today
Document database:
Schema linh hoạt.
Tốt về performance cục bộ: Ví dụ website của bạn cần load thông tin về một entry, nếu data được lưu ở nhiều table khác nhau, việc join sẽ tốn thời gian
Gần với cấu trúc dữ liệu của application.
Relation database: Hỗ trợ join tốt hơn trong mối quan hệ: many-to-one and many-to-many
Ngôn ngữ truy vấn cho data

Ngôn ngữ truy vấn declarative và imperative
SQL tạo ra một ngôn ngữ truy vấn mới ngôn ngữ “khai báo” (declarative query language). Khác với các ngôn ngữ lập trình IMS and CODASYL, truy vấn cơ sở dữ liệu bằng cách sử dụng mã lệnh mệnh lệnh (imperative). Vậy sự khác biệt là gì?
Giải bạn có một danh sách các loài động vật (animals), và muốn lấy ra một list các “Sharks”. Ví dụ với một imperative ta có hàm như sau:
function getSharks() {
var sharks = [];
for (var i = 0; i < animals.length; i++) {
if (animals[i].family === "Sharks") {
sharks.push(animals[i]);
}
}
return sharks;
}Với SQL, một ngôn ngữ declarative sẽ có dạng:
SELECT * FROM animals WHERE family = 'Sharks';Với imperative language, ta cần chỉ rõ cho máy tính cách thức thực hiện một tác vụ (HOW). Ví dụ như trong trường hợp trên, ta phải viết vòng lặp, so sánh các biến, rồi lưu kết quả vào một danh sách.
Trong khi đó, với declarative language, ta chỉ cần mô tả dữ liệu mà mình muốn lấy (WHAT). Chẳng hạn: “lấy dữ liệu có family là Sharks”, mà không cần quan tâm đến việc truy vấn được thực hiện như thế nào. Phần việc tối ưu hóa — như chọn chỉ mục hay chiến lược tìm kiếm — sẽ do hệ quản trị cơ sở dữ liệu quyết định.
Declarative language có lợi thế là dễ dàng song song hóa và cho phép hệ thống tự tối ưu truy vấn. Ngược lại, với imperative language, việc tối ưu là rất khó, bởi nó tập trung vào từng bước thực thi chi tiết thay vì mô tả mẫu dữ liệu mà ta cần.
MapReduce Querying

Là một programming model tạo bới Google cho xử lý một lượng lớn data, thành từng bulk, trong nhiều máy tính.
Ví dụ, hãy tưởng tượng bạn là một nhà sinh vật biển, và mỗi lần quan sát thấy động vật dưới đại dương, bạn lại thêm một bản ghi vào cơ sở dữ liệu. Giờ đây, bạn muốn tạo một báo cáo cho biết mỗi tháng bạn đã nhìn thấy bao nhiêu con cá mập.
Với PostgreSQL, bạn có thể viết một câu query như thế này:
SELECT date_trunc('month', observation_timestamp) AS observation_month, sum(num_animals) AS total_animals
FROM observations
WHERE family = 'Sharks' GROUP BY observation_month;Câu query trên, đầu tiên sẽ lọc nhưng dòng có family = 'Sharks' sau đó group lại theo observation_month và tính tổng giá trị num_animals
Trong MongoDB’s MapReduce feature:
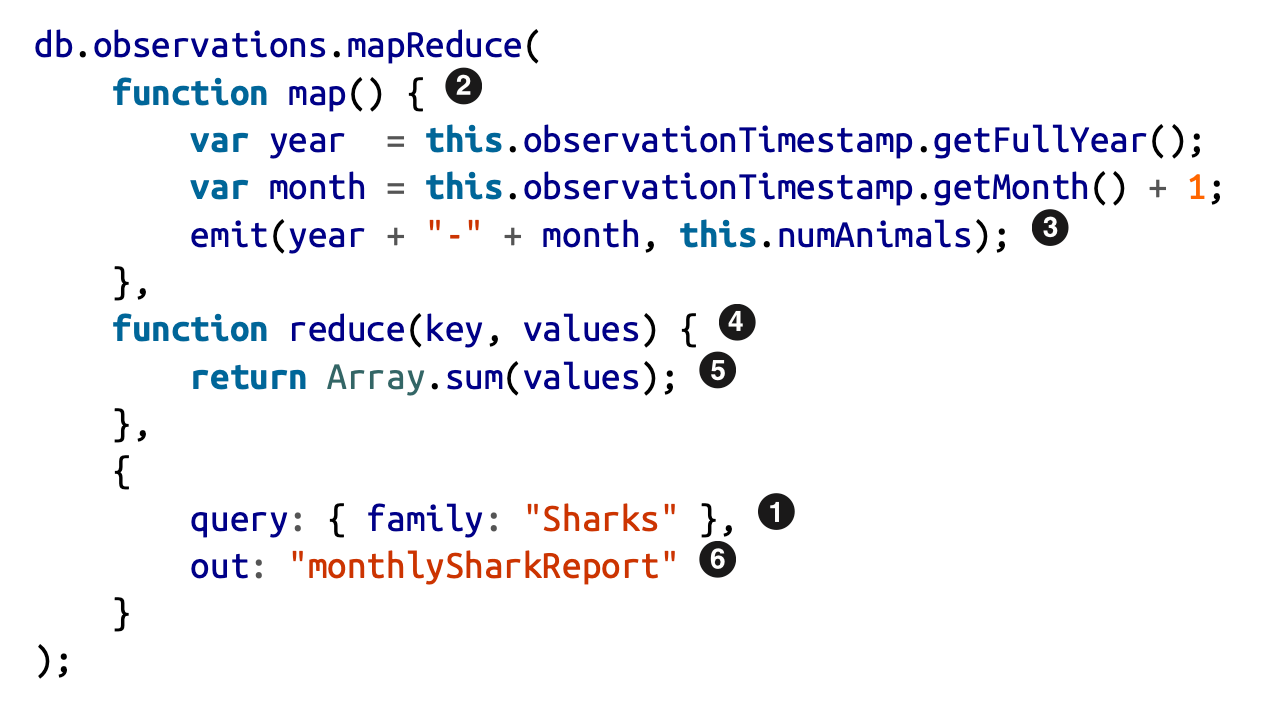
Giả sử chúng ta có dữ liệu như sau
{
observationTimestamp: Date.parse("Mon, 25 Dec 1995 12:34:56 GMT"),
family: "Sharks",
species: "Carcharodon carcharias",
numAnimals: 3
}
{
observationTimestamp: Date.parse("Tue, 26 Dec 1995 10:11:12 GMT"),
family: "Sharks",
species: "Delphinus Sharks",
numAnimals: 4
}Map function sẽ được gọi cho mỗi document, trả về giá tri emit("1995-12", 3) and emit("1995-12", 4). Sau đó reduce function sẽ được gọi reduce("1995-12", [3, 4]) và trả về 7.
The map and reduce function, giống như là một imperative languge, chúng nói cách thức data được xử lý (HOW). Và chúng phải là function thuần, nghĩa là chúng chỉ được sử dụng input data, và không thể thực hiện thêm câu query database nào khác để truy vấn thêm dữ liệu. Những ràng buộc này cho phép cơ sở dữ liệu có thể chạy các hàm ở bất kỳ đâu, theo bất kỳ thứ tự nào, và chạy lại chúng khi xảy ra lỗi.
Graph-Like Data Models
Nếu như ứng dụng của bạn hầu hết chỉ có one-to-many relationship (dạng cây) hoặc không có quan hệ giữa các record, document model là một lựa chọn tốt.
Nhưng nếu có quá nhiều mối quan hệ many-to-many, relational database có thể giúp bạn handle những trường hợp đơn giản. Nhưng nếu connection giữa các record trở lên phức tạp, graph data có thể là lựa chọn tiếp theo của bạn để model hoá data.
Một đồ thị gồm 2 objects: vertices - nút (nodes hoặc entities) và edges - cạnh (relationships). Có rất nhiều ví dụ về graph data model:
Social graphs: vertices là con người, nếu hai người bất kỳ biết nhau, sẽ có cạnh nối giữa họ
The web graph: vertices là những trang web, edges nếu có HTML link tới trang đó.
Lưu ý: Trong một đồ thị (graph), có thể tồn tại nhiều loại đỉnh (vertices) và cạnh (edges) khác nhau.
Ví dụ:
Vertices có thể là con người, địa điểm hoặc sự kiện.
Edges có thể biểu diễn mối quan hệ giữa hai người, hoặc hành động một người thực hiện check-in tại một địa điểm.
Trong phần này chúng ta sẽ sử dụng ví dụ sau để mô tả các dặc tính của graph-like model.
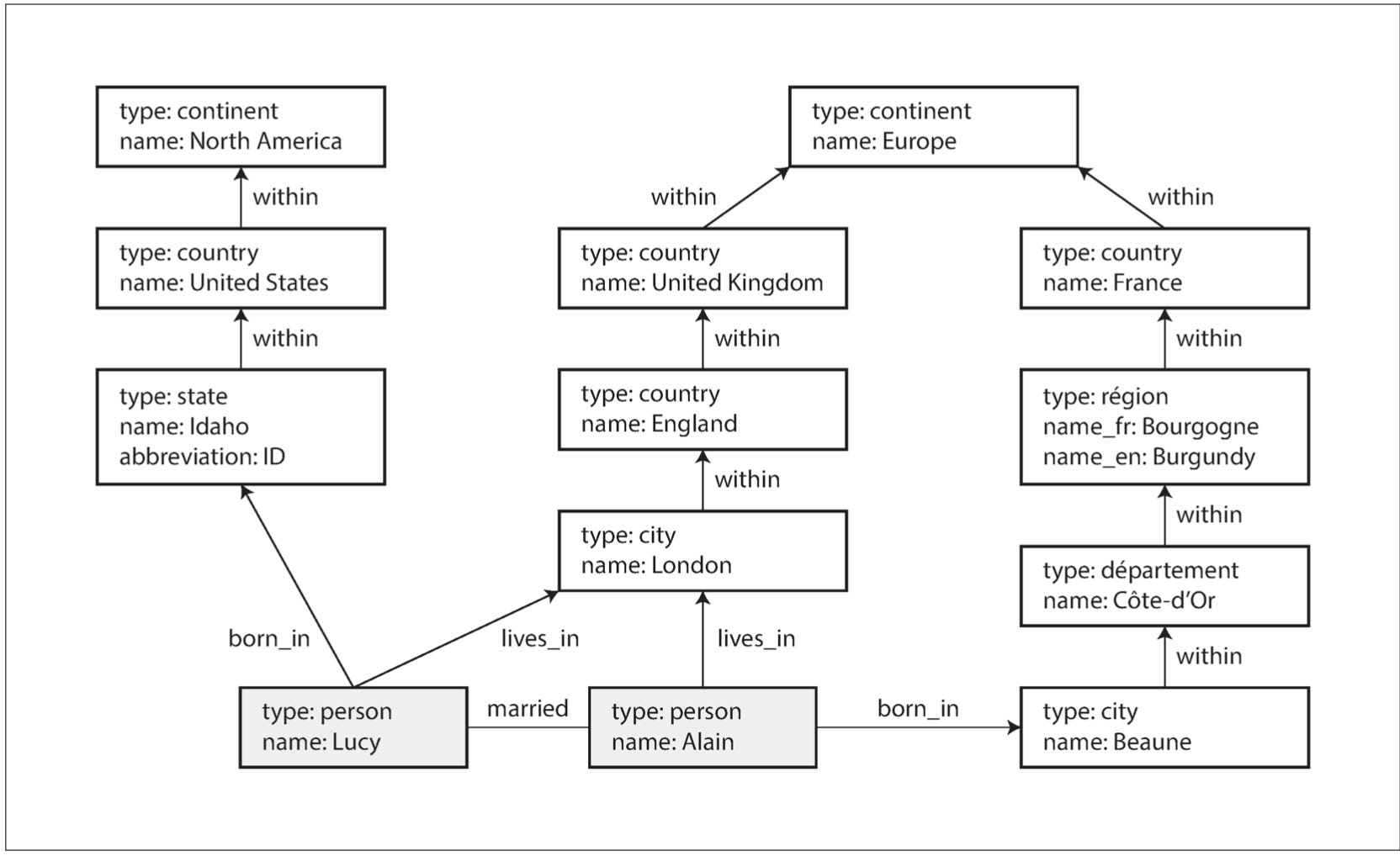
Chúng ta có thể lưu thông tin của graph trên trong SQL bằng cách tạo 2 tables vertices và edges như sau:
CREATE TABLE vertices (
vertex_id INTEGER PRIMARY KEY,
properties JSON
);
CREATE TABLE edges (
edge_id INTEGER PRIMARY KEY,
tail_vertex INTEGER REFERENCES vertices (vertex_id),
head_vertex INTEGER REFERENCES vertices (vertex_id),
label TEXT,
properties JSON
);
CREATE INDEX edges_tails ON edges (tail_vertex);
CREATE INDEX edges_heads ON edges (head_vertex);
Bất cứ node nào (vertices) có thể tạo edges liên kết tới bất kỳ vertices nào, không có ràng buộc nào về các loại vertices có thể connect tới
Cho bất kỳ một vertex nào, chúng ta có thể dễ dàng tìm ra các edges đến và đi, đó là lý do vì sao phải có 2 một tail_vertex and head_vertex ở table edges trên
Bằng cách thêm các thuộc tính vào cột label và properties, chúng ta có thể dễ dàng thêm cái loại relationship khác nhau mà vẫn giữ được structure của graph.
Khi put data graph vô SQL, việc query có thể có gặp một vài khó khăn. Trong relation database, chúng ta đã biết sẵn table nào join với table nào. Nhưng trong graph data, chúng ta phải duyệt qua rất nhiều edges để biết được vertex nào để join. Trong ví dụ của chúng ta, một edge LIVES_IN của một người có thể trỏ đến nhiều loại địa điểm khác nhau: đường, thành phố, quận, vùng, bang, Ví dụ: Một thành phố có thể nằm trong một vùng, vùng đó lại nằm trong một bang, bang nằm trong một quốc gia, … Nói cách khác, cạnh LIVES_IN có thể trỏ trực tiếp đến đỉnh địa điểm mà bạn đang tìm, hoặc có thể cách vài cấp trong hệ thống phân cấp địa lý.
The Cypher Query Language
Cypher là một declarative query language, đùng để định nghĩa graph và sau đó có thể query trong đó. Được dùng trong Neo4j graph database.
Summary
Mô hình dữ liệu là một chủ đề rất rộng, và trong chương này chúng ta đã điểm qua nhanh một loạt các mô hình khác nhau. Chúng ta không có đủ không gian để đi sâu vào tất cả chi tiết của từng mô hình, nhưng hy vọng phần tổng quan này đã đủ để khơi gợi hứng thú, giúp bạn tìm hiểu thêm về mô hình nào phù hợp nhất với yêu cầu của ứng dụng của mình.
Hy vọng bài viết này đã mang đến cho bạn một vài góc nhìn mới về system design. Nếu có thắc mắc, đừng ngần ngại để lại bình luận – mình luôn sẵn sàng trao đổi thêm.
Nếu bạn thấy nội dung hữu ích, hãy subscribe để nhận thêm những chia sẻ chuyên sâu về kiến trúc hệ thống và microservices. Và nếu muốn ủng hộ mình có thêm động lực để viết nhiều hơn, bạn có thể mời mình một ly ☕ qua
– mình sẽ rất trân trọng!
Hay quas anh
Haha, quá chuẩn