
Queues và logs
Cũng tìm hiểu về hai khái niệm này và xem sự khác nhau và các ứng dụng của chúng.

Lược dịch từ blog: https://jack-vanlightly.com/blog/2023/10/2/the-advantages-of-queues-on-logs
It’s logs all the way down
“A log is perhaps the simplest possible storage abstraction. It is an append-only, totally-ordered sequence of records ordered by time”. Jay Kreps.
Mọi thứ trong thế giới công nghệ đều bắt nguồn từ logs.
Các hệ quản trị cơ sở dữ liệu phổ biến như MySQL hay PostgreSQL sử dụng write-ahead logs (WAL) để đảm bảo tính atomicity và durability của giao dịch.
Các hệ thống dữ liệu phân tán hiện đại cũng dựa vào log như một thành phần cốt lõi để ghi nhận và đồng bộ trạng thái giữa các node.
Queues, tới lượt mình, cũng là một cấu trúc dữ liệu có tính FIFO và giữ được thứ tự của các element, nhưng điểm khác biệt chủ yếu giữa logs và queues là:
Trong queue, consumer chỉ cần yêu cầu phần tử tiếp theo, và queue sẽ chịu trách nhiệm xác định và trả về giá trị đó. Consumer hoàn toàn không cần biết về cấu trúc bên trong của queue – nó chỉ đơn giản là hỏi: “Giá trị tiếp theo là gì?”
Ngược lại, với logs, consumer đọc dữ liệu dựa trên vị trí (offset) cụ thể trong log. Do logs không tự động xoá phần tử sau khi đã được đọc (khác với queue), consumer cần tự theo dõi và ghi nhớ vị trí mà nó đang đọc để có thể tiếp tục từ đúng điểm đó trong lần tiếp theo.
Logs rất thích hợp cho use-case khi bạn muốn mọi consumer đọc từ đầu tới cuối, không được bỏ xót item nào trong logs.
Queue thì ngược lại khi bạn muốn consumer chia sẽ work-load. Mỗi consumer sẽ đọc một phần queue items. Vì vậy queue rất thích hợp cho những việc liên quan tới load distribution.
Queue and log basics
Queue
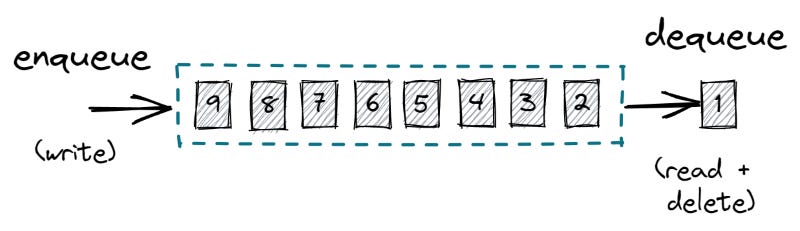
Queue là kiêu dữ liệu First-In-First-Out và dữ liệu được xoá sau khi được đọc bởi reader.
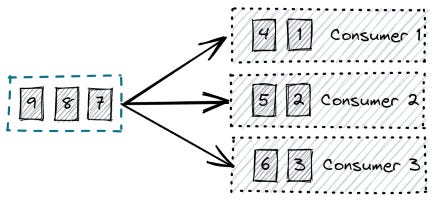
Vì tính chất item được xoá sau đi consumer đọc, chúng ta có thể tạo nhiều consumer để consume item từ queue mà không cần quan tâm cấu trúc bên trong của queue. Và chúng ta không cần lo lắng item nào bị đọc hai lần.
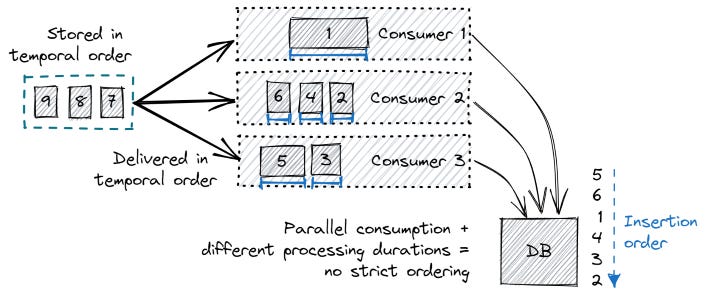
Nhưng đó cũng là điểm yếu của queue, ví dụ chúng ta quan tâm tới order của các item khi các consumers xử lý song song.
Bản thân queue lưu trữ các items theo đúng thứ tự ban đầu của nó, nhưng việc chúng ta xử lý song song bằng nhiều consumer đã làm mất đi tính thứ tự của items.
Logs
Logs cũng giống như queue những có một khác biệt cơ bản, logs không có xoá item sau khi đọc consume. Consumer có thể đọc đi đọc lại bao nhiêu lần tuỳ thích.
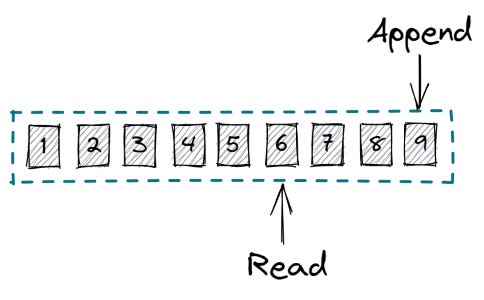
Cũng giống như queue, logs có thể hỗ trợ nhiều consumers, nhưng khác với queue, mỗi consumer của log phải đọc từng item một
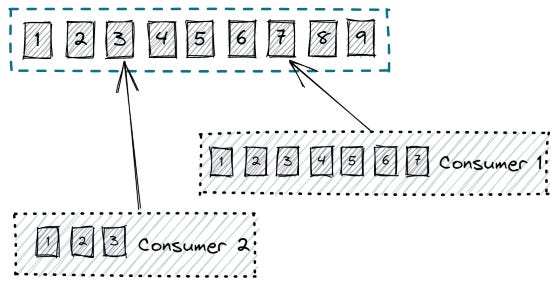
Vậy là thế nào để scale up lên với logs?
Câu trả lời là chia nhỏ logs ra thành nhiều partition logs. Producers có thể chọn gửi item vô bất cứ logs partition nào, có thể là round-robin hoặc hash function …
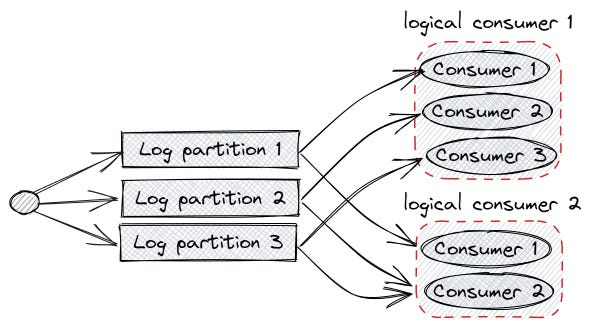
Durable queues and logs over a network
Trong queue, hai thao tác read và delete cần được thực hiện một cách nguyên tử (atomic). Nếu item được đọc nhưng consumer bị crash vơi khi hoàn tất xử lý, thì khi khôi phục, item đó có thể bị đọc lại — dẫn đến việc xử lý lặp (xử lý nhiều hơn một lần). Ngược lại, nếu consumer vừa đánh dấu là đã xử lý xong rồi gặp sự cố, thì dữ liệu có thể bị mất hoàn toàn. Đây chính là đặc trưng của cơ chế xử lý at-most-once — tối đa một lần.
Để đảm bảo được at-least-once, queue cần phải lưu thêm trạng thái của cái item. Đó là mục đích của việc acknowledge (ACK message)
Replay
Làm thế nào nếu chúng ta muốn đọc lại toàn bộ items? Ví dụ nhưng muốn backfill process. Queue không hỗ trợ việc này. Tuy nhiên, với Logs, chúng ta chỉ đơn giản là điều chỉnh vị trí đọc mà chúng ta mong muốn.
Xây dựng queues dựa trên logs
Chúng ta có thể xây dựng queue interface và data thực sự được lưu trên logs. Như vậy chúng ta có thể kết hợp được những ưu điểm của cả queue và logs.
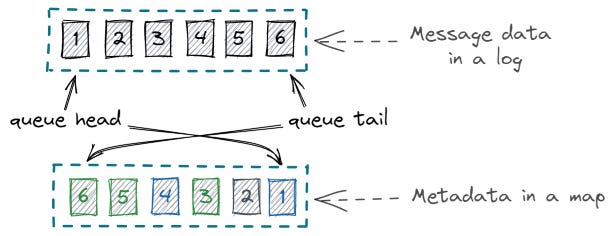
Mỗi khi một message được đưa vào queue, hệ thống cần lưu lại trạng thái xử lý của message đó. Phần trạng thái này không nằm trong nội dung message mà được lưu dưới dạng metadata. Trong mô hình kết hợp với logs, ta có thể lưu message trong log, còn metadata (như trạng thái đã đọc, ack, retry, timeout...) thì lưu trong queue để quản lý riêng biệt.
Nhiều consumer đồng nghĩa với việc mỗi consumer sẽ có một queue riêng biệt, nơi lưu trữ metadata riêng, hoàn toàn độc lập với các consumer khác. Cách tiếp cận này cho phép chúng ta tạo ra nhiều hàng đợi ảo (virtual queues) cùng hoạt động trên một log chung. Nhờ đó, ta có thể dễ dàng giải quyết các bài toán như playback và đảm bảo các cơ chế xử lý như at-most-once hoặc at-least-once cho mỗi queue. Vì data đã được lưu ở logs, không bị xoá đi, khi cần playback ta chỉ cần update lại metadata ở mỗi virtual queue tưng ứng.
Kết luận
Ranh giới giữa logs và queue dần được xoá nhoà nhờ việc xây dựng queue trên logs. Queues có thể thực hiện được những thứ logs làm và ngược lại.
Trong bài viết này, chúng ta khám phá cách xây dựng một hệ thống queue đáng tin cậy dựa trên logs. Thay vì xoá message sau khi đọc như queue truyền thống, mô hình này tách riêng message (lưu trong log) và metadata (lưu trong queue), giúp hỗ trợ nhiều consumer độc lập, giữ thứ tự xử lý, và đảm bảo các cơ chế như at-most-once, at-least-once, hay playback dễ dàng hơn. Đây là nguyên lý đứng sau các hệ thống như Kafka, Pulsar, hay Google Pub/Sub.
Nếu có bất kì câu hỏi nào, đừng ngần ngại để lại comment
Đọc thêm:
https://jack-vanlightly.com/blog/2023/10/2/the-advantages-of-queues-on-logs