
Xây dựng một ứng dụng Retrieval Augmented Generation (RAG) - P1
Hướng dẫn xây dựng một chatbot bằng RAG đơn giản


Một ứng dụng RAG thường gồm 2 bước:
Indexing: Tích hợp, lưu trữ và xử lý dữ liệu thô có sẵn, thường làm offline
Retrieval and generation: RAG chain thực sự bắt đầu. Lấy user input tại runtime, tìm kiếm các documents liên quan từ phần index, sau đó bỏ vào model.
Indexing
Load: Load toàn bộ dữ liệu, sử dụng document loaders (https://python.langchain.com/docs/concepts/document_loaders)
Split: Chia document lớn thành nhiều chunk nhỏ hơn. Những splits này được dùng cả ở bước indexing và retrieval. (https://python.langchain.com/docs/concepts/text_splitters/)

Source: https://python.langchain.com/docs/tutorials/rag/ Store: Lưu trữ splits documents và vectors tương ứng cho việc sử dụng sau này. Có hai bước nhỏ:
Embedding model: giúp chuyển đổi ngôn ngữ tự nhiên của con người thành dạng mà máy móc có thể hiểu được — cụ thể là các vector số học có độ dài cố định. Những mô hình này nhận đầu vào là văn bản, sau đó biến đổi thành vector để hệ thống có thể thực hiện việc tìm kiếm tài liệu tương ứng, không chỉ dựa trên từ khóa, mà còn theo ngữ nghĩa của câu.
Vector store: indexing and retrieving information based on vector representations. EX: pgvector in Postgress


Retrieval and generation
Retrieve: Dự vào user input, truy vấn những splits liên quan bằng cách sử dụng các retrievers (https://python.langchain.com/docs/concepts/retrievers/)
Generation: LLM/ChatModel tạo ra những câu trả lời bằng cách kết hợp câu hỏi và data từ bước retrieval.

Trong ví dụ này, chúng ta sẽ sử dụng LangGraph (https://langchain-ai.github.io/langgraph/) framework để thức hiện việc retrieval và generation.
Hướng dẫn chi tiết
Trong ví dụ này, chúng ta sẽ load thông tin từ blog https://lilianweng.github.io/posts/2023-06-23-agent/ sau đó đặt các câu hỏi liên quan cho LLM/Chat model.
Indexing
Loading
Chúng ta sẽ sử dụng WebBaseLoader và Beautifulsoup4 để extract data từ blog, nội dung gồm: post-title, post-header, post-content
import bs4
from langchain_community.document_loaders import WebBaseLoader
# Only keep post title, headers, and content from the full HTML.
bs4_strainer = bs4.SoupStrainer(class_=("post-title", "post-header", "post-content"))
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs={"parse_only": bs4_strainer},
)
docs = loader.load()
assert len(docs) == 1
print(f"Total characters: {len(docs[0].page_content)}") # Total characters: 43047Splitting documents
Chúng ta có 43k characters, quá lớn để bỏ vào bất cứ model nào, cho dù có thể bỏ vô thì cũng quá lớn để tìm kiếm thông tin một cách chính xác. Vì vậy chúng ta cần tách ra thành nhiều splits nhỏ hơn.
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, # chunk size (characters)
chunk_overlap=200, # chunk overlap (characters)
add_start_index=True, # track index in original document
)
all_splits = text_splitter.split_documents(docs)
print(f"Split blog post into {len(all_splits)} sub-documents.") # Split blog post into 63 sub-documents.Embedding and store
import os
os.environ["GOOGLE_API_KEY"] = "...." # your Google API key
from langchain_google_genai import GoogleGenerativeAIEmbeddings
from langchain_core.vectorstores import InMemoryVectorStore
embeddings = GoogleGenerativeAIEmbeddings(model="models/gemini-embedding-001")
vector_store = InMemoryVectorStore(embeddings)
# Index chunks
document_ids = vector_store.add_documents(documents=all_splits)
print("document_ids: ", document_ids[:3])Trong ví dụ này, chúng ta sử dung model `gemini-embedding-001` của Google để embedding data. Và để cho đơn giản, chúng ta sẽ sử dung InMemoryVectorStore để lưu trữ vectors sau khi embedding.
Retrieval and generation
Bây giờ mới vào logic thực sự của application. Lấy câu hỏi của users, tìm kiếm những documents liên quan, bỏ những documents đó và câu hỏi vào model để lấy câu trả lời tưng ứng.
Đầu tiền, chúng ta tạo một prompt từ LangChain prompt hub
from langchain import hub
# N.B. for non-US LangSmith endpoints, you may need to specify
# api_url="https://api.smith.langchain.com" in hub.pull.
prompt = hub.pull("rlm/rag-prompt")
example_messages = prompt.invoke(
{"context": "(context goes here)", "question": "(question goes here)"}
).to_messages()
assert len(example_messages) == 1
print(example_messages[0].content)
## ChatPromptTemplate(input_variables=['context', 'question'], input_types={}, partial_variables={}, metadata={'lc_hub_owner': 'rlm', 'lc_hub_repo': 'rag-prompt', 'lc_hub_commit_hash': '50442af133e61576e74536c6556cefe1fac147cad032f4377b60c436e6cdcb6e'}, messages=[HumanMessagePromptTemplate(prompt=PromptTemplate(input_variables=['context', 'question'], input_types={}, partial_variables={}, template="You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.\nQuestion: {question} \nContext: {context} \nAnswer:"), additional_kwargs={})])Sử dụng LangGraph, chúng ta sẽ:
Định nghĩa state của ứng dụng. State sẽ định nghĩa data của các bước input, transform và output
Node (Từng bước của ứng dụng)
Control flow ( thứ tự từng step)
State
Một state đơn giản trong ứng dụng, bao gồm các câu hỏi, context tương ứng và câu trả lời.
from langchain_core.documents import Document
from typing_extensions import List, TypedDict
class State(TypedDict):
question: str
context: List[Document]
answer: strNodes (các steps của ứng dụng)
def retrieve(state: State):
retrieved_docs = vector_store.similarity_search(state["question"])
return {"context": retrieved_docs}
def generate(state: State):
docs_content = "\n\n".join(doc.page_content for doc in state["context"])
messages = prompt.invoke({"question": state["question"], "context": docs_content})
response = llm.invoke(messages)
return {"answer": response.content}Retrieve: Tìm kiếm documents tưng ứng với câu hỏi
Generate: Format documents và bỏ câu hỏi vào model.
Control flow
Cuối cùng, chúng ta kết hợp tất cả vào một graph object bằng hàm compile() và sau đó có thể dùng hàm build-in để visualizing control flow
from langgraph.graph import START, StateGraph
graph_builder = StateGraph(State).add_sequence([retrieve, generate])
graph_builder.add_edge(START, "retrieve")
graph = graph_builder.compile()
from IPython.display import Image, display
display(Image(graph.get_graph().draw_mermaid_png()))Kết quả:
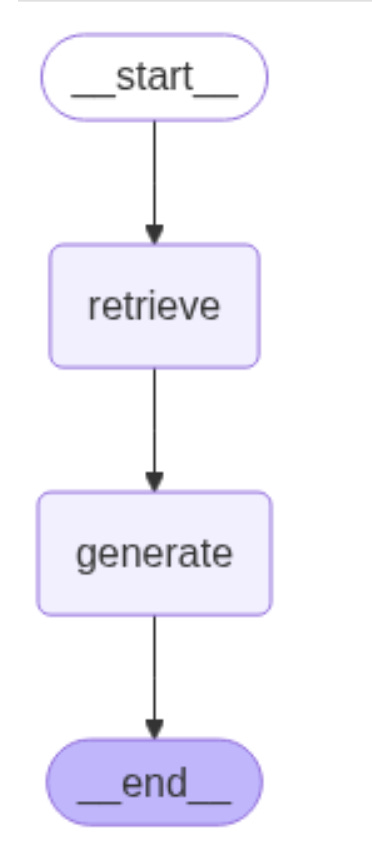
Và test thử bằng cách gọi hàm invoke() từ graph object
result = graph.invoke({"question": "What is Task Decomposition?"})
print(f"Context: {result['context']}\n\n")
print(f"Answer: {result['answer']}")
## Output:
Context: [Document(id='5406e348-7863-476b-818f-0804bb673853', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/', 'start_index': 2578}, page_content='Task decomposition can be done (1) by LLM with simple prompting like "Steps for XYZ.\\n1.", "What are the subgoals for achieving XYZ?", ....... 'https://lilianweng.github.io/posts/2023-06-23-agent/', 'start_index': 34990}, page_content='Conversatin samples:\n[\n {\n "role": "system",')]
Answer: Task decomposition is a technique used to break down complex tasks into smaller, simpler, and more manageable steps. This process enhances model performance by allowing more test-time computation. It can be achieved by prompting a model to "think step by step," using task-specific instructions, or with human input.Stream:
Từng bước trong graph được in ra theo thứ tự khi định nghĩa graph.
for step in graph.stream(
{"question": "What is Task Decomposition?"}, stream_mode="updates"
):
print(f"{step}\n\n----------------\n")
## Output:
{'retrieve': {'context': [Document(id='5406e348-7863-476b-818f-0804bb673853', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/', 'start_index': 2578}, ...... Document(id='ea3fc648-fd55-435e-9b23-0bda2a3bf736', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/', 'start_index': 34990}, page_content='Conversatin samples:\n[\n {\n "role": "system",')]}}
----------------
{'generate': {'answer': 'Task decomposition is a process of breaking down complex or hard tasks into smaller, simpler, and more manageable steps. This technique, often associated with Chain of Thought (CoT) prompting, enhances model performance by instructing a model to "think step by step." It transforms big tasks into multiple manageable sub-tasks.'}}Query analysis
Chúng ta đã thực hiện truy vấn trực tiếp từ input gốc của người dùng. Tuy nhiên, trong một số hệ thống phức tạp, chúng ta có thể yêu cầu mô hình viết lại câu truy vấn từ yêu cầu ban đầu của người dùng để bổ sung các yếu tố tìm kiếm ngữ nghĩa — ví dụ như giới hạn kết quả trong các tài liệu từ năm 2020.
Query analysis là một kỹ thuật yêu cầu model transform or construct optimized search queries từ raw user input.
Ví dụ, với những documents lấy từ ví dụ trước, chúng ta thêm một thuộc tính mới vào metadata tên là “section”.
total_documents = len(all_splits)
third = total_documents // 3
for i, document in enumerate(all_splits):
if i < third:
document.metadata["section"] = "beginning"
elif i < 2 * third:
document.metadata["section"] = "middle"
else:
document.metadata["section"] = "end"
all_splits[0].metadata
## Output:
{'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/',
'start_index': 8,
'section': 'beginning'}Reindex all vector in vector_store
from langchain_core.vectorstores import InMemoryVectorStore
vector_store = InMemoryVectorStore(embeddings)
_ = vector_store.add_documents(all_splits)Sau đó, chúng ta định nghĩa một schema cho Search query. Bao gồm câu raw query và section enum chứa một trong ba giá trị: begging, middle and end.
from typing import Literal
from typing_extensions import Annotated
class Search(TypedDict):
"""Search query."""
query: Annotated[str, ..., "Search query to run."]
section: Annotated[
Literal["beginning", "middle", "end"],
...,
"Section to query.",
]Cuối cùng, thêm một step trong graph để generate query từ user input
class State(TypedDict):
question: str
query: Search
context: List[Document]
answer: str
def analyze_query(state: State):
structured_llm = llm.with_structured_output(Search)
query = structured_llm.invoke(state["question"])
return {"query": query}
def retrieve(state: State):
query = state["query"]
retrieved_docs = vector_store.similarity_search(
query["query"],
filter=lambda doc: doc.metadata.get("section") == query["section"],
)
return {"context": retrieved_docs}
def generate(state: State):
docs_content = "\n\n".join(doc.page_content for doc in state["context"])
messages = prompt.invoke({"question": state["question"], "context": docs_content})
response = llm.invoke(messages)
return {"answer": response.content}
graph_builder = StateGraph(State).add_sequence([analyze_query, retrieve, generate])
graph_builder.add_edge(START, "analyze_query")
graph = graph_builder.compile()Sau đó visualization để xem graph structure, chúng ta có thể thấy một step mới tên là “analyze_query” đã được thêm vào trước bước retrieve
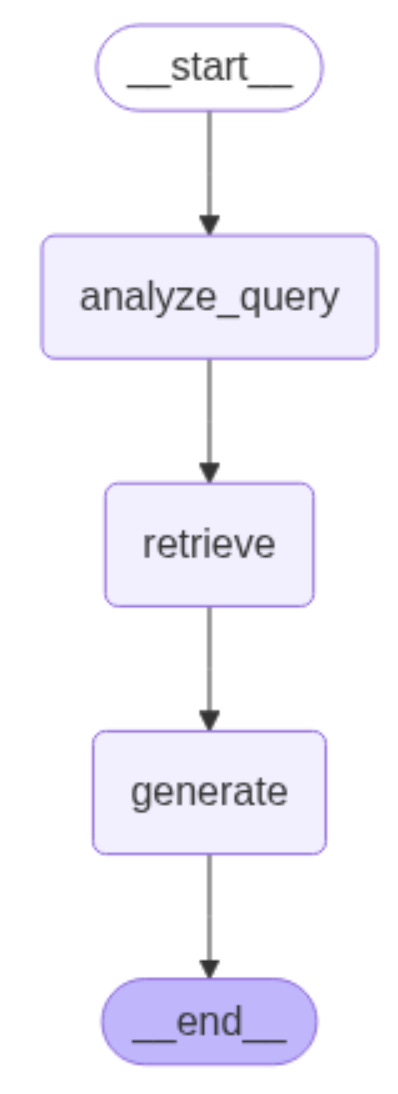
Test graph bằng cách gọi hàm stream()
for step in graph.stream(
{"question": "What does the end of the post say about Task Decomposition?"},
stream_mode="updates",
):
print(f"{step}\n\n----------------\n")
## Output:
{'analyze_query': {'query': {'query': 'Task Decomposition', 'section': 'end'}}}
----------------
{'retrieve': {'context': [Document(id='0bb0e312-2892-4495-ab3a-fef698bb7263', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/', 'start_index': 38621, 'section': 'end'}, page_content='are imported by that file, and so on.\\nFollow a language and framework appropriate best practice file naming convention.\\nMake sure that files contain all imports, types ....., Document(id='205d8589-3a34-41fc-bb5f-376a43ed602b', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/', 'start_index': 39002, 'section': 'end'}, page_content='}\n]\nChallenges#\nAfter going through key ideas and demos of building LLM-centered agents, I start to see a couple common limitations:')]}}
----------------
{'generate': {'answer': "I'm sorry, but the provided text does not mention Task Decomposition. Therefore, I cannot tell you what the end of the post says about it."}}Chúng ta có thể thấy từng step được in đúng như những gì chúng ta mong đợi
Kết luận
Chúng ta đã đi qua những chủ để:
Load document
Text Splitter
Embedding data
Retrieving
Sinh ra câu trả lời từ user input và retrieving document
Trong phần 2 chúng ta sẽ cải thiện theo dang trao đổi như giữa người với người.
Nếu bạn có thắc măc gì xin đừng ngần ngại để lại câu hỏi
Đọc thêm
https://python.langchain.com/docs/introduction/
https://python.langchain.com/docs/tutorials/rag/